通过Data Augmentation把CIFAR10的训练精度提升到89%
条评论我们先来回顾一下上一次的训练结果:
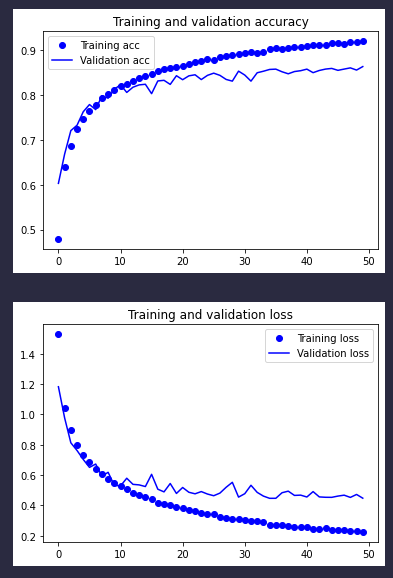
可以看到在训练不到20批的时候,训练精度就与测试精度分道扬镳了。这算是一种过拟合。目前我们手上的工具箱也就剩数据增强还没用了。理论上数据增强可以弥补训练集太小的问题,从而缓解过拟合的现象。实话说,在实际操作中,这种方法已经被检验过有效了。但是总给人一种用一种机器去欺骗另一种机器的感觉,我个人觉得,机械化的数据增强应该早晚被更优秀的训练模型所取代。
闲话少说,我们来看下最终的效果:
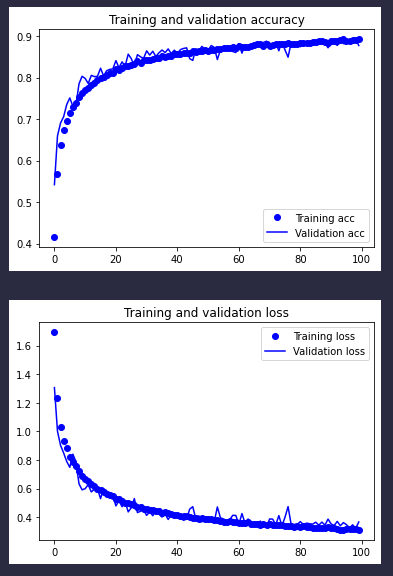
这是训练了100批的效果(足足花费了我43分49秒),前几次的训练都是到50批我就觉得差不多了。这次 一开始我也是用的50,但是当我发现训练精度被验证精度咬得死死的时候,我就又训练了100批的,也就是上面的结果。
可以看到,虽然从40批开始,训练进步的幅度就开始放缓了,但是整个训练还一直向好的方向上前进,过拟合现象也得到了抑制。基本在100批的时候,我们已经有了一个验证精度在88%~89%的模型,总的来说还是有效果的。
下面看下数据增强的核心代码:
from keras.preprocessing.image import ImageDataGenerator |
上面的代码基本上就是照抄keras官方文档的一节,不过我们的模型与文档还是有很大不同,毕竟是我们一步步探索出来的,最终模型代码如下:
from keras import layers |
有了数据增强后,我们训练模型的代码要稍加改动:
model.compile(optimizer='Adam', |
最后再说一下,我用的optimizer(优化器)是Adam,跟上面提到的keras文档里用的RMSprop还是有区别的。根据我实际测试下来,Adam的学习速度还是要好于RMSprop的。
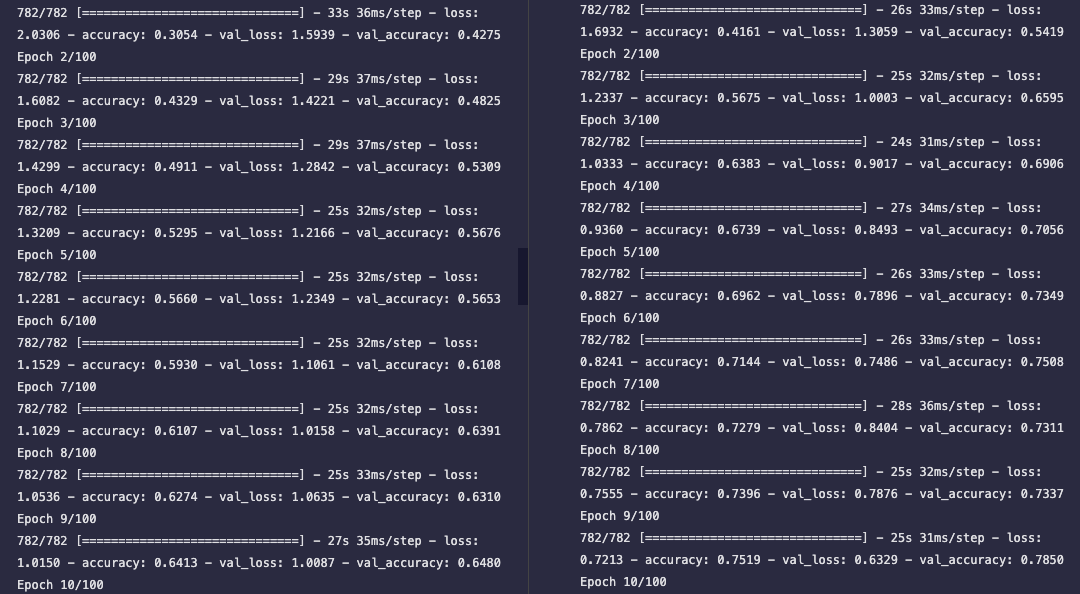
左图是RMSprop,右图是Adam(也就是我们上面实际在跑的结果)。通过对比我们可以看出来,10批之后,Adam的训练精度就达到了75%,而RMSprop的训练精度还仅有64%。所以把Adam作为一个默认选项会是一个挺好的选择,这也是我们在前几次训练中使用的。
本文标题:通过Data Augmentation把CIFAR10的训练精度提升到89%
文章作者:牧云踏歌
发布时间:2022-04-28
最后更新:2022-04-28
原始链接:http://www.kankanzhijian.com/2022/04/28/cnn-cifar10-try-5-data-augmentation/
版权声明:本博客文章均系本人原创,转载请注名出处