使用简单的CNN训练CIFAR10,理解padding='same'的含义
条评论今天在训练CIFAR10数据的时候,稍微调整了下网络,对卷积层增加了padding,最终结果得到了一定的改善:
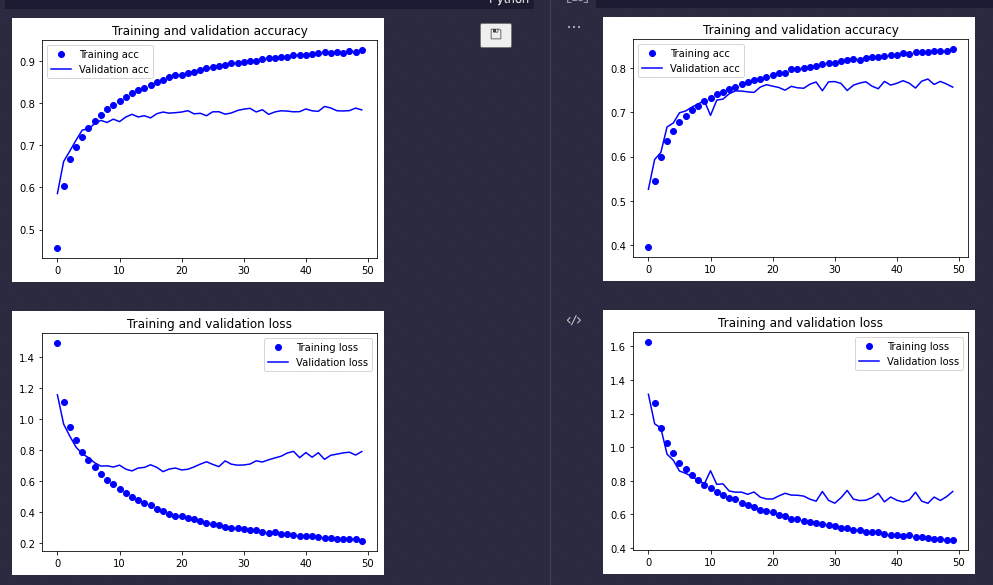
上图左边,是增加了padding='same'的结果,右图是上一次的模型。可以看到左边的训练精度明显好于右侧。而验证精度也略好于右侧。
参考keras的文档:
padding: one of “valid” or “same” (case-insensitive). “valid” means no padding. “same” results in padding with zeros evenly to the left/right or up/down of the input. When padding=”same” and strides=1, the output has the same size as the input.
padding设置为true后,会对输入的上下左右进行填充,并且如果strides(步幅)设置为1后,输入与输出的大小应该相同。如果拿4*4的输入为例,用3*3的卷积以步幅为1进行运算时。应该在上下左右四边每边补充一组数据,形成一个6*6的输入,这样在和3*3做以步幅为1做卷积的时候,输出才会是4*4(6-3+1=4)。
回到本例,CIFAR10的原始大小是32*32的,如果没有padding='same',那么在与3*3做步幅为1的卷积时,输出的大小就应该是32-2,也就是30*30了。
关于padding参数的解释就到这,至于为什么增加padding之后,训练的结果朝着更好的方向发展。或者说,如果不提供padding,会使训练结果变差,在《深度学习入门 基于Python的理论与实现》这本书中有这样的解释:
如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能为1,导致无法再应用卷积运算。
基于这种极限化的考虑,那么在每次卷积之后,保证输出大小不变就是必要的了。
不过我在测试API使用中还遇到一个问题,如果strides大于1,那么padding='same'也是无法保证输出与输入大小相同的。这个虽然在keras文档里说了,但是我却有点困惑,觉得这有悖于same的字面意思,只能留着以后再研究了。
最后附上今天使用的核心代码:
from keras import layers |
本文标题:使用简单的CNN训练CIFAR10,理解padding='same'的含义
文章作者:牧云踏歌
发布时间:2022-04-14
最后更新:2022-04-14
原始链接:http://www.kankanzhijian.com/2022/04/14/cnn-cifar10-try-2/
版权声明:本博客文章均系本人原创,转载请注名出处